特征工程之手动特征衍生
在细致进行探索性数据分析后,我们需要基于察觉到的分布规律,以及数据集的特点构造一些新的特征。这些新特征可以帮助模型更好地理解数据,提高模型的预测能力,这个过程称为特征工程(Feature Engineering)。
特征工程可以说是建模中最重要的环节,相比于模型的选择和调参,特征工程往往能够带来更大的提升,也是能够拉开差距的最关键环节。
当然,上一节中探索性分析的过程,也可以看作是特征工程的一部分,这些了解可以帮助我们构造更加有效的特征。
特征衍生
NOTE
以下特征均可以通过上一节中介绍的绘制特征与标签的分布图,观察其分布规律,以及特征之间的关系来构造。这里省略绘图观察过程。
-
年龄风险
-
薪资与年龄比
-
时薪风险
-
距离风险
-
司龄风险
-
历史工作经历
-
平均任职时长
-
职业跳槽风险
-
综合风险
衍生特征相关性
在创建了这些特征之后,我们可以绘制相关性系数来验证一下这些特征是否有效。
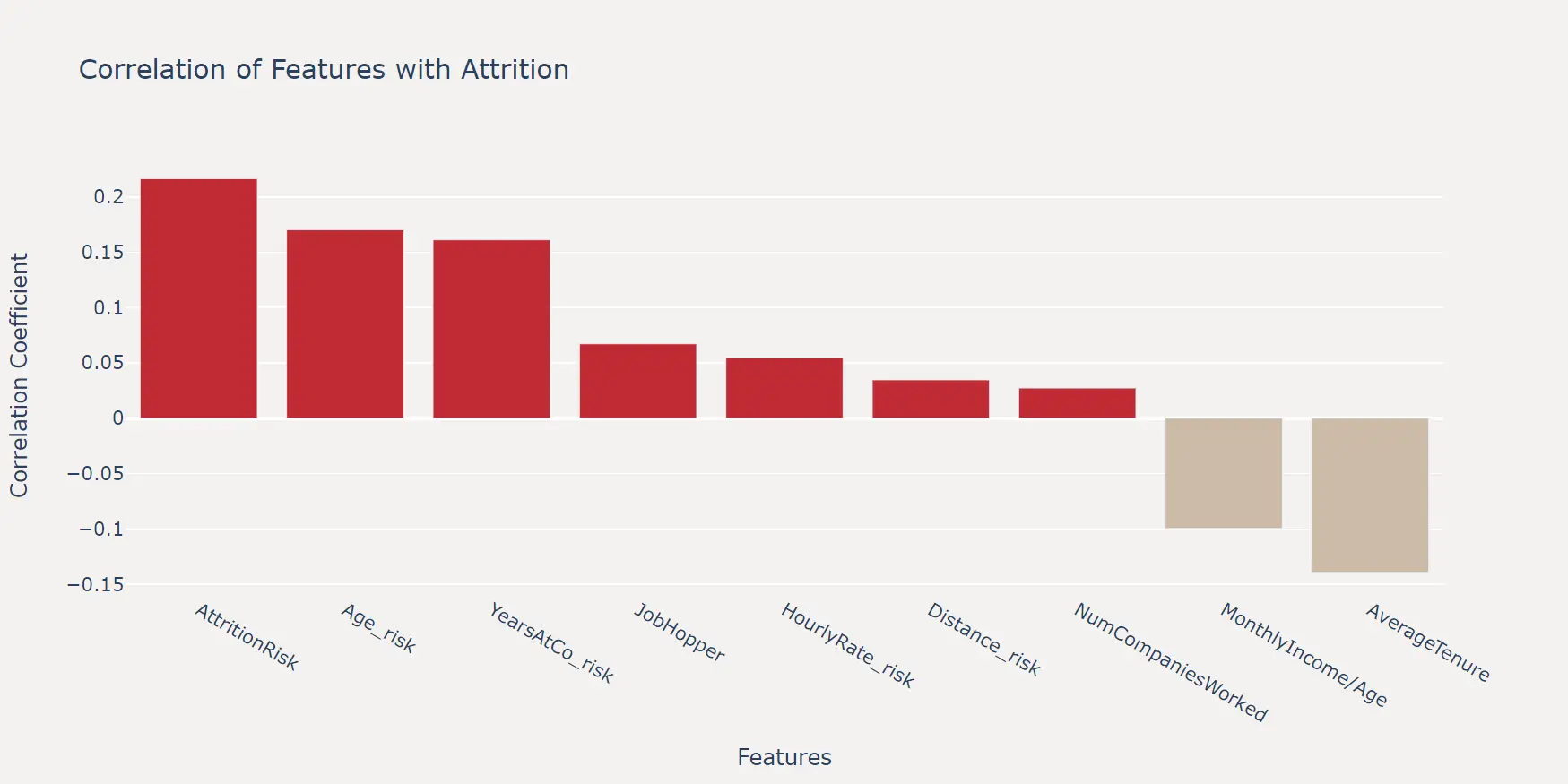
可以看出,我们构造的特征还是比较有效的,尤其是最终汇总的 AttritionRisk 特征,与标签的相关性高于原始数据集的任何特征。
ON THIS PAGE