通常我们会人工搜索并阅读大量的新闻报告,不仅耗费人力和时间,且容易遗漏重要信息。在大模型的加持下,我们可以通过爬虫技术加上大模型的理解能力,自动化这一过程,从而提高效率。
环境准备
由于晚点网页是动态加载的,需要使用Selenium来模拟浏览器行为。首先安装Selenium并下载Chrome驱动 ChromeDriver Download。
ChromeDriver注意选择对应平台的版本,下载后解压到当前路径下或指定目录。
初始化 WebDriver 并打开网页
使用 Selenium 初始化 WebDriver,并设置 Chrome 为无头模式,这样可以在后台运行。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
# 设置 Chrome 选项
chrome_options = Options()
chrome_options.add_argument('--headless')
# 初始化 WebDriver
webdriver_path = '' # 我这里把 WebDriver 放在当前目录下,如果放在其他目录,需要指定路径
driver = webdriver.Chrome(service=Service(executable_path=webdriver_path), options=chrome_options)
# 打开网页
driver.get('https://www.latepost.com/')
time.sleep(3) # 等待页面完全加载
获取新闻
网站中的新闻链接存储在特定的标签中,在浏览器中可以通过检查元素找到对应的标签。把鼠标放在新闻标题上,右键选择检查,可以看到对应的 HTML 结构。
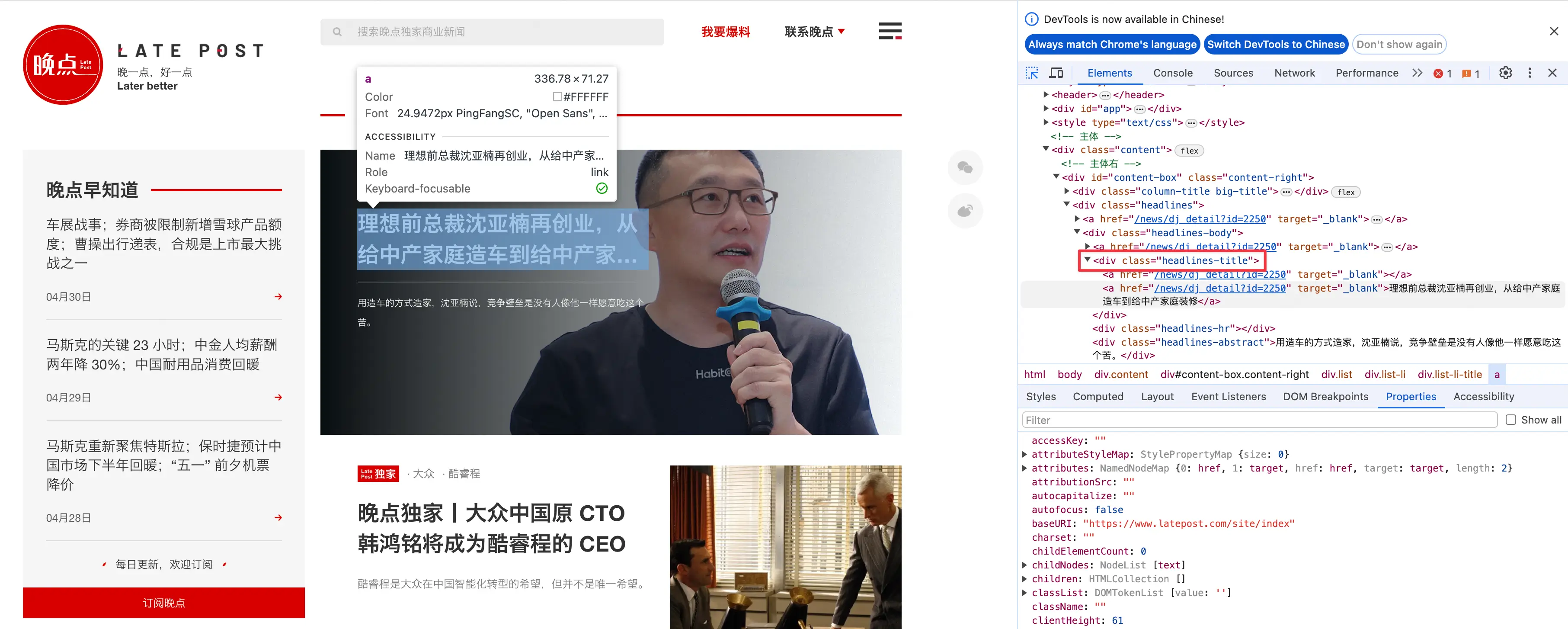
而晚点网站中,一共有三种类型的新闻,分别是头条、新闻报道、晚点早知道,对应的标签分别是headlines-title、list-li-title、Newsletter-li。我们可以通过 XPath 或 css selector 来定位这些标签。
# 使用 css selector 提取特定新闻元素
css_selector = ".headlines-title a, .list-li-title a, .Newsletter-li a"
news_links = driver.find_elements(By.CSS_SELECTOR, css_selector)
获取新闻标题和链接
为便于后续处理,我们把新闻标题和链接存储在一个字典中。
articles = {}
# 收集所有新闻的标题和链接
for link in news_links:
articles[link.get_attribute('href')] = link.text # 链接为 key,标题为 value
效果如下:
articles
{'https://www.latepost.com/news/dj_detail?id=2250': '理想前总裁沈亚楠再创业,从给中产家庭造车到给中产家庭装修',
'https://www.latepost.com/news/dj_detail?id=2257': '晚点独家丨大众中国原 CTO 韩鸿铭将成为酷睿程的 CEO',
'https://www.latepost.com/news/dj_detail?id=2254': '长城汽车建双销体系:转型不靠有样学样',
'https://www.latepost.com/news/dj_detail?id=2253': '晚点独家丨出海电商四小龙竞赛:翻倍增长,用一切办法',
'https://www.latepost.com/news/dj_detail?id=2251': '丰田调整在华策略,南北丰田工厂齐减产',
'https://www.latepost.com/news/dj_detail?id=2248': '供应链新军丨德赛西威:不想被淘汰,就得自己颠覆自己',
'https://www.latepost.com/news/dj_detail?id=2258': '车展战事;券商被限制新增雪球产品额度;曹操出行递表,合规是上市最大挑战之一\n04月30日',
'https://www.latepost.com/news/dj_detail?id=2256': '马斯克的关键 23 小时;中金人均薪酬两年降 30%;中国耐用品消费回暖\n04月29日',
'https://www.latepost.com/news/dj_detail?id=2255': '马斯克重新聚焦特斯拉;保时捷预计中国市场下半年回暖;“五一” 前夕机票降价\n04月28日'}
筛选新闻日期
实际应用中,根据更新的周期,我们只需要最近一段时间的新闻,需要根据发布时间对文章进行筛选,案例中我们获取最近10天的新闻。
由于首页的标题中没有日期信息,我们需要逐个链接进入文章页面获取发布日期。文章发布日期存储在article-header-date标签中,但不是标准的日期格式。
import time
# 设置希望获取最近几天的新闻
today = datetime.today()
n_days_ago = today - timedelta(days=10)
# 检查每个文章的发布日期
for url, title in list(articles.items()):
driver.get(url)
time.sleep(3)
date_element = driver.find_element(By.CLASS_NAME, "article-header-date")
date_text = date_element.text.split(' ')[0] # 获取日期部分,格式为 "04月29日"
date_formatted = f"{date_text.replace('月','-').replace('日','')}" # 转换日期格式为 "04-29"
article_date = datetime.strptime(f"{today.year}-{date_formatted}", "%Y-%m-%d") # 解析日期
# 仅保留最近n天的文章
if article_date < n_days_ago:
del articles[url]
执行后,我们只保留了最近10天的新闻,字典中的文章数量从9篇减少到6篇。
articles
{'https://www.latepost.com/news/dj_detail?id=2257': '晚点独家丨大众中国原 CTO 韩鸿铭将成为酷睿程的 CEO',
'https://www.latepost.com/news/dj_detail?id=2254': '长城汽车建双销体系:转型不靠有样学样',
'https://www.latepost.com/news/dj_detail?id=2253': '晚点独家丨出海电商四小龙竞赛:翻倍增长,用一切办法',
'https://www.latepost.com/news/dj_detail?id=2258': '车展战事;券商被限制新增雪球产品额度;曹操出行递表,合规是上市最大挑战之一\n04月30日',
'https://www.latepost.com/news/dj_detail?id=2256': '马斯克的关键 23 小时;中金人均薪酬两年降 30%;中国耐用品消费回暖\n04月29日',
'https://www.latepost.com/news/dj_detail?id=2255': '马斯克重新聚焦特斯拉;保时捷预计中国市场下半年回暖;“五一” 前夕机票降价\n04月28日'}
关闭 WebDriver
完成所有操作后,不要忘记关闭 WebDriver,释放资源。