大模型高效微调(一)训练集准备
在某些场景下,我们希望大模型掌握一些固有知识,或希望提升小参数模型在执行相对标准化任务上的表现,可以采用模型微调的方法。
关于模型微调
大模型发展一年来,模型微调从技术上已经变成了一件比较容易的事情,像 LLaMA-Factory 这样的工具,甚至提供了可视化的训练界面,几乎可以零门槛实现模型微调。
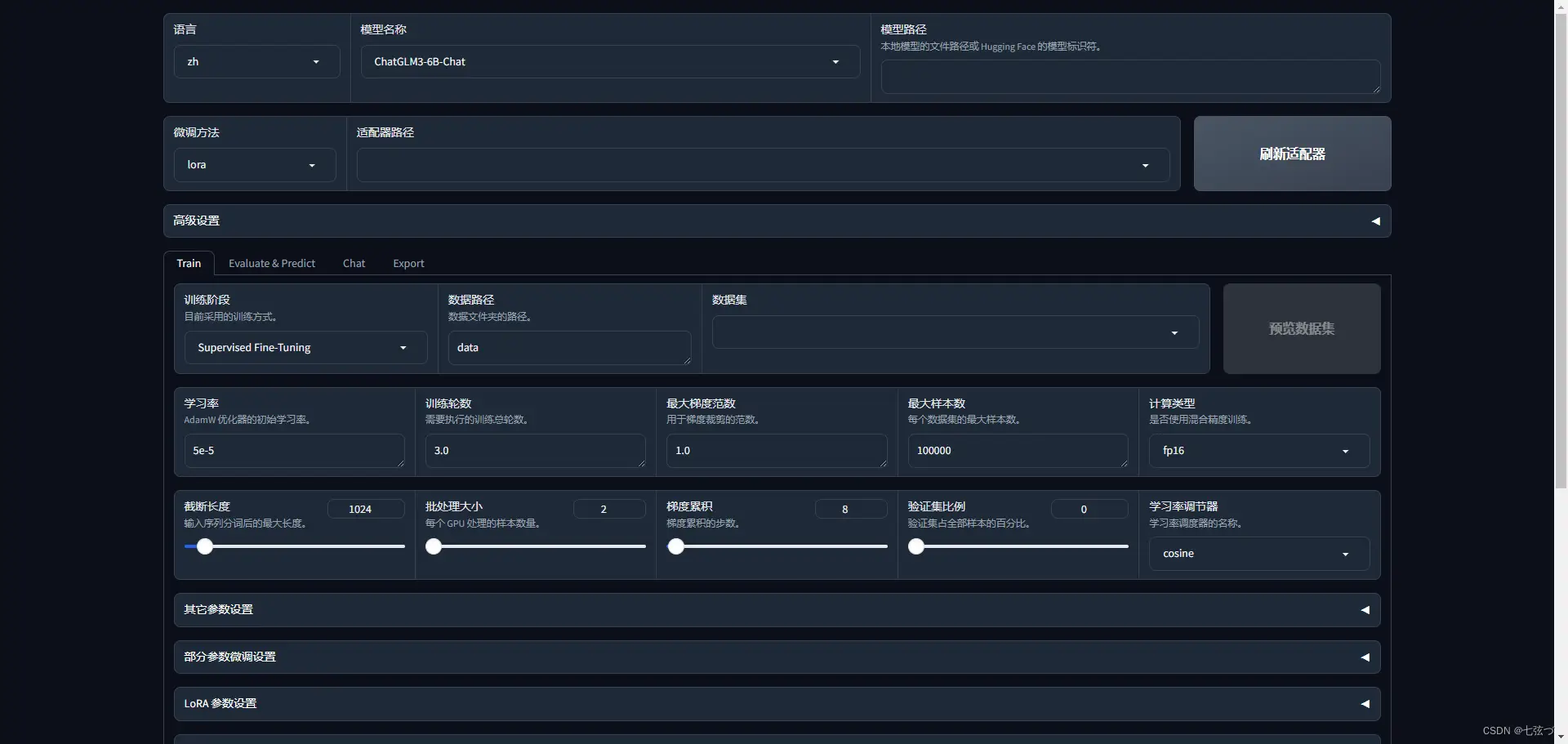
因此,当前模型微调的关键,其实是训练数据集的处理和质量提升。
训练集生成
由于我们训练的都是对话模型,因此提供给模型的训练数据集,应该是一系列问答对。
一般来说,问答数据主要有两种来源:
- 基于企业中真实的对话数据,包括工作中的答疑记录整理等。
- 将现有文档数据,通过大模型或工程化的手段转化为问答数据。
这里我们以第二种方式为例,选取刚刚发布的《全球人力资本趋势报告-德勤》这份报告,尝试将其微调进入模型中。
利用大模型基于文档生成问答对
分页载入文档
使用 PDFPlumberLoader 可以将 PDF 文档分页载入,可以看到载入后的数据是一个列表,一共有120页。
Output
设计大模型任务
这里简单设计一个任务,每一次输入一个文档页,另大模型基于这一页的内容生成5个问答对。实际应用中可以根据诉求设计更完善的任务。
执行任务
TIP
这一段代码需要根据实际情况进行调整。
- 其中
clean_list_data函数是由于模型输出的结果是一段 markdown 格式的代码块,需要将其转化为列表。实际清洗方式根据模型实际输出格式进行调整。 - 完成这个任务需要较长时间,使用了
tqdm进行进度展示。 - 由于模型很可能会出现错误,如输出格式不准确、上下文长度超出限制等,因此使用
try...except进行异常处理,在出现错误时继续执行下一轮。
格式化数据
一般来说,模型训练需要接收 json 格式的数据,使用 LoRA 方法微调时,数据格式要求如下:
因此,我们需要将上一步生成的数据转化为这种格式。
保存到本地:
CAUTION
注意添加参数 ensure_ascii=False,以确保中文字符不被转义。
效果展示
最终生成的数据样本如下:
NOTE
由于没有对问答数据的生成进行充分调优,可以发现生成的数据对于原文来说,效果并不是很好,仅作为实现思路上的参考。
下一篇将继续介绍模型微调训练及效果测试。
ON THIS PAGE